

This week we take a look at LLMs that need therapists, governance of machine learning hardware, and benchmarks for dangerous behaviour. Read to the end to join great Summer programmes and research projects in AI safety.
We also introduce our newsletter's design change along with the Spanish translation of our newsletter, made possible by the help of the amazing Aitana and Alejandro. Ve a suscribirte! Write if you are interested in helping out as well.
You receive the Apart Newsletter since you have previously subscribed to any of our newsletters. If you want to manage which types of emails you receive from us, e.g. hackathon or weekly AI safety research updates, go to news.apartresearch.com.
Do the rewards justify the means?
Pan et al. (2023) introduce the Measuring Agents’ Competence & Harmfulness In A Vast Environment of Long-horizon Language Interactions (MACHIAVELLI) benchmark which contains more than half a million realistic high-level action scenarios. Check out an example below.

They find that if agents are explicitly trained to get the most reward in the text-based games, they will be less ethical than random agents. The researchers also introduce simple ways to make the agents more ethical. Read more on the project website.
Governing compute with firmware
Shavit recently published his proposal for how we can ensure the safety of future AI and make auditing machine learning (ML) model training possible. It proposes a three-step plan:
Producers install firmware on ML training hardware (such as all GPUs produced) to log neural network weights in a way that does not cost much and maintains privacy for the owners.
By checking these logs, inspectors can easily see if someone has broken any rules limiting training of ML systems.
Countries ensure that this firmware is installed by monitoring the ML hardware supply chains.
This is one of the first concrete, promising, and in-depth proposals for monitoring and safeguarding ML development in the future.

Overview of the proposed monitoring framework
Defending against training data attacks
Patch-based backdoor attacks in neural networks work by including replacing small areas of images in the training set of ML models with a type of trigger, e.g. seven yellow pixels in the bottom left corner, to make it classify and image incorrectly if that trigger shows up. For example, it might classify a dog picture as a cat if the seven yellow pixels are present.
The PatchSearch algorithm is a way to use the model trained on the dataset to identify and filter out any training data that seems to be changed (or "poisoned") to create this trigger in the model. They then retrain the model on the filtered data. We recommend looking into the paper to see their specific implementation. This type of work is important in removing training data that can lead to intentionally or unintentionally uncontrollable models.
Language models can solve computer tasks
The MiniWoB++ benchmark is a benchmark with over 100 web interaction tasks. Researchers recently outperformed the previously best algorithms by using large language models with a prompting design they call recursive critique and output improvement (RCI).
By prompting the model to critique its own performance and improve its output based on this critique, they outperform models trained on the same benchmark with reinforcement learning and supervised learning. They also find that combining RCI with chain-of-thought prompting works even better.
Therapists for language models
Lin et al. (2023) introduce their SafeguardGPT chatbot architecture consisting of GPT-based models interacting with each other in the roles of User, Chatbot, Critic and Therapist. It is an interesting experiment in using human-like interaction to make language models more aligned.
The Chatbot is intentionally made to be slightly misaligned (in this case, narcissistic) compared to its job (described in the prompt) of providing guidance and service to the user. At any point in the conversation, it has the ability to enter into a therapy session with the Therapist and change its responses to the User. Afterwards, the Critic creates a reward signal for the Chatbot based on its evaluations of manipulation, gaslighting, and narcissism present in the Chatbot's answers.
As prompting becomes more and more important, it seems clear that we need to establish good ways to model these prompting architectures, such as the Constitutional AI approach where an AI overlooks its own actions based on rules created by humans.
AI updates
When it comes to updates in artificial intelligence, there are already way too many to list in a single week, and we suggest you follow channels such as Yannic Kilcher, Nincompoop, AI Explained, and Zvi. Here are a few of the more relevant ones:
Anthropic investment documents have been leaked and show their 4-year plans to spend $5B to create the tentatively named "Claude-Next", a language model ten times the size of GPT-4. Meanwhile, their current language model Claude is seen in more and more services and now in the Zapier no-code tool.
Stanford releases a large report on the state of AI.
A recent survey of language model research provides a good overview of the latest developments within research on language models, and if you are curious to dive deeper, we recommend reading it.
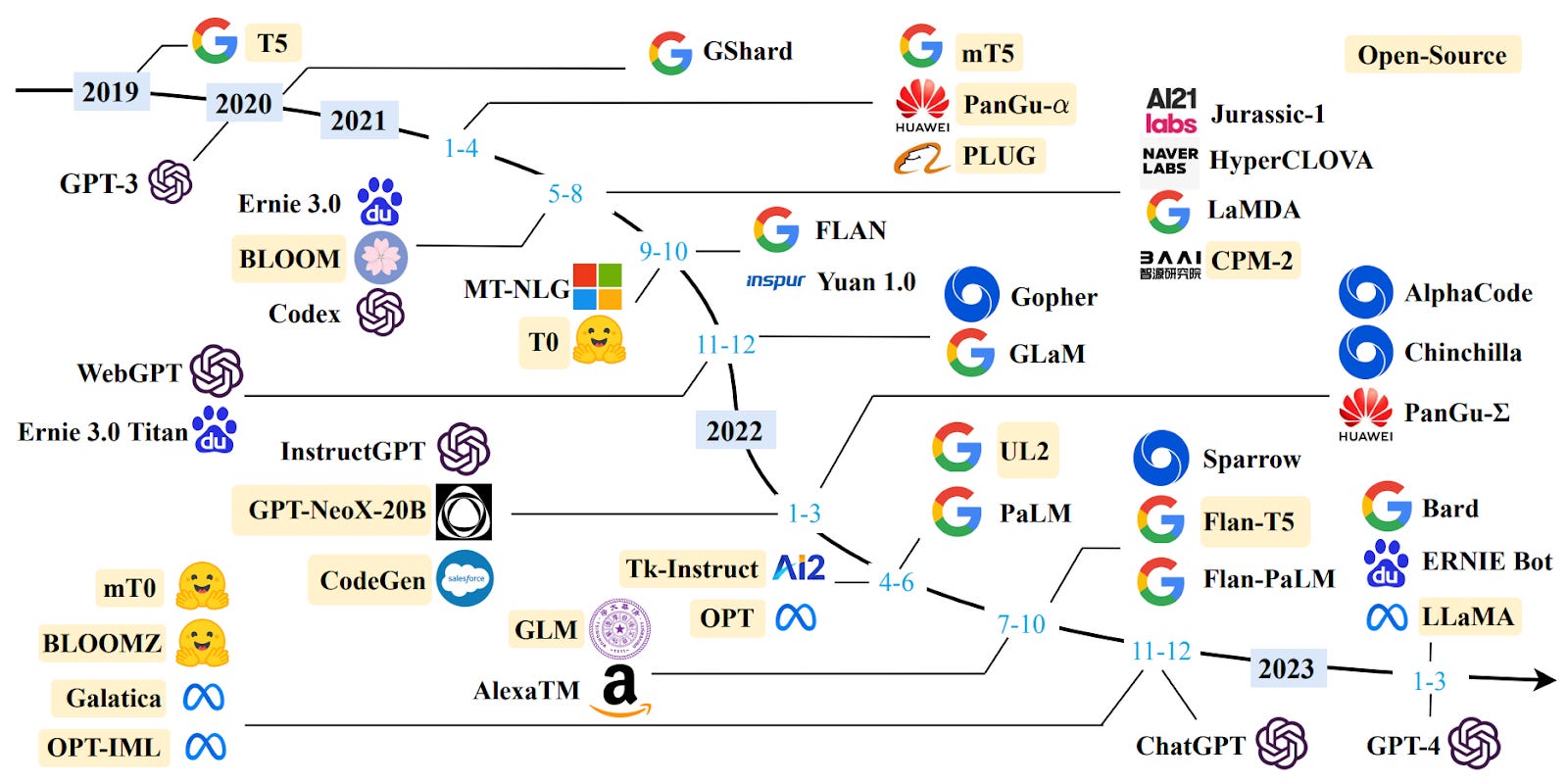
Major models of the past few years. Yellow indicates open source (source).
Join great AI safety programmes
You now have the chance to become part of creating tomorrow's research in AI safety as part of these training programmes:
SERI MATS is a 3-month training programme where you get direct mentorship and guidance from researchers at top institutions within ML and AI safety, like Anthropic, FHI, MIRI, CAIS, DeepMind and OpenAI. Apply now for their Summer cohort!
You are now invited to join the Cooperative AI Summer School, happening in early June, focused on providing early-career individuals with an introduction to Cooperative AI.
The Alignment Research Center is hiring for a range of positions, e.g. machine learning researcher, model interaction contractor, operations roles, and human data leads.
Join our hackathon with Neel Nanda where you get the chance to work directly on research in interpretability. If you create a promising project, you get the chance for collaboration and mentorship through our Apart Lab program afterwards! So come join with your friends virtually or at one of the in-person locations.
Remember to share this newsletter with your friends who are interested in ML and AI safety research and subscribe to our new Spanish newsletter as well.
See you all next week!