
Identifying semantic neurons, mechanistic circuits & interpretability web apps
Results from the 4th Alignment Jam

15 research projects on interpretability were submitted to the mechanistic interpretability Alignment Jam in January hosted with Neel Nanda. Here, we share the top projects and results. In summary:
Activation patching works on singular neurons, token vector and neuron output weights can be compared, and a high mutual congruence between the two indicates a mono-semantic MLP neuron.
The Automatic Circuit Identification tool (ACDC) can be used to infer a circuit for gendered pronouns, and some of these circuits can perform even better than the full model. Hyperparameter tuning for ACDC is also very important.
A three-stage method can be used to automatically identify semantically coherent neurons and describe in human-understandable language what that neuron activates to.
Several tokens that complete the same task with GPT-2 prompts can be replaced with token coordinates between their positions that accomplish the same task with acceptable performance.
Other projects include comparisons of compiled and trained Transformers, web apps for mechanistic interpretability, latent knowledge regularizers, and embedding attention heads.
Join the interpretability hackathon 2.0 happening this weekend.
We Found " an" Neuron
By Joseph Miller and Clement Neo
Abstract (from the subsequent LessWrong post): We started out with the question: How does GPT-2 know when to use the word "an" over "a"? The choice depends on whether the word that comes after starts with a vowel or not, but GPT-2 can only output one word at a time. We still don’t have a full answer, but we did find a single MLP neuron in GPT-2 Large that is crucial for predicting the token " an". And we also found that the weights of this neuron correspond with the embedding of the " an" token, which led us to find other neurons that predict a specific token.
First, they use the logit lens to identify a multi-layer perceptron (MLP) layer in the Transformer where the difference between predicting " an" and " a" is the largest (logit is a way of representing the model's probability for what the next token should be).
They then use activation patching (Meng et al, 2022) to see how specific layers in the model contribute to the prediction of " an". In activation patching, you save the activations on a prompt such as "I climbed the apple tree and picked[...]" and replace these saved activations in a run with "I climbed the lemon tree and picked[...]" for each layer. Since you predict " an" and " a" for these prompts respectively, we can then see how layers contribute to predicting " an".
The main findings occur in the next steps, where they find that:
Activation patching works on singular neurons
We can calculate the output congruence for tokens and neuron weights (see below)
If a neuron and a token is mutually congruent, i.e. the neuron is mainly congruent with that single token and vice versa, we can find the most neurons that activate the most cleanly to singular tokens

Neel’s comment (to the hackathon project): Very cool project! This aligns with what max activating dataset examples finds: https://www.neelnanda.io/anneuron (it should be on neuroscope but I ran out of storage lol) I'm generally pretty surprised that this worked lol, I haven't seen activation patching seriously applied to neurons before, and wasn't sure whether it would work. But yeah, really cool, especially that it found a monosemantic neuron! I'd love to see this replicated on other models (should be pretty easy with TransformerLens) Tbh, the main thing I find convincing in the notebook is the activation patching results, I think the rest is weaker evidence and not very principled. Some nit picks: - ablation means setting to zero, not negating. Negating is a somewhat weird operation that seems maybe more likely to break things? Neuron activations are never significantly negative, because GELU tends to give positive outputs. IMO the most principled is actually a mean or random ablation (described in https://neelnanda.io/glossary ) We already knew that the residual had high alignment with the neuron input weights, because it had a high activation! Just plotting the neuron activation over the text would have been cool, likewise plotting it over some other randomly chosen text. It'd have been interesting to look at the direct effect on the logits, you want to do W_out[neuron_index, :] @ W_U and look at the most positive and negative logits. I'm curious how much this composes with later layers vs just directly contributing to the logits It would also have been interesting to look at how the inputs to the layer activate the neuron. But yeah, really cool work! I'm surprised this worked out so cleanly. I'm curious how many things you've tried? I think this would be a solid thing to clean up into a blog post and a public Colab, and I'd be happy to add it to a page of cool examples of people using TransformerLens Oh, and the summary under-sells the project. "Encoding for an" sounds like it activates ON an, not that it predicts an. The second is much cooler! -Neel
See the code and research (original submission).
Identifying a Preliminary Circuit for Predicting Gendered Pronouns in GPT-2 Small
By Chris Mathwin and Guillaume Corlouer
Abstract: We identify the broad structure of a circuit that is associated with correctly predicting a gendered pronoun given the subject of a rhetorical question. Progress towards identifying this circuit is achieved through a variety of existing tools, namely Conmey’s Automatic Circuit Discovery and Nanda’s Exploratory Analysis tools. We present this report, not only as a preliminary understanding of the broad structure of a gendered pronoun circuit, but also as (perhaps) a structured, re-implementable procedure (or maybe just naive inspiration) for identifying circuits for other tasks in large transformer language models. Further work is warranted in refining the proposed circuit and better understanding the associated human-interpretable algorithm.
They use Conmy, 2022's tool for automatic circuit identification (ACDC) that uses path patching (a variant of the activation patching described earlier) to identify the circuit that represents gendered pronouns. It requires several steps:
Generate a dataset of examples; mark important token positions in the sentences; and create a counter-dataset where the model cannot infer gender from the names. This is used for the corrupted activation patching, as described in the previous project.
Define metric to measure model's task performance and choose a threshold value for ACDC to balance performance and not inferring a large, cluttered circuit. Construct the circuit using ACDC where each rectangle represents a specific computational component (e.g. attention head or MLP) at a specific token position:

Evaluate the performance of this isolated circuit compared to the whole model. The one shown above has 65% as good performance while only using 5% of the model's (head, token) pairs.
They find a smaller circuit as well along with a circuit that performs better than the full model, despite being smaller.
Neel’s comment: Fun project! Nice work, and cool to see my demo + ACDC used in the wild :) I think the 5% of (head, position) components used figure is a bit inflated - my guess is that most tokens in the sentence don't actually matter to the task, so that automatically disqualifies many (head, position) pairs (I'd love to be proven wrong!). I found the claim that name -V> is -K> 't matters a lot interesting, in particular the importance of the key connection - this is surprising to me! I'm guessing there's some kind of grammatical circuit? I also appreciated the discussion of the importance of the threshold in finding the algorithm, interesting to see the importance of this kind of hyper-parameter tuning, and I think this kind of empirical finding is an important contribution. My guess is that what's going on is that there's a significant chunk of the circuit devoted to realising that there's a name in the previous sentence, and a pronoun that comes next, and to attend to the name, and then some extra effort to look up the gender of that name and map it to a pronoun. I would personally have made a baseline distribution with a name of the opposite gender rather than "That person" to control for the "discover it's a pronoun identification task + find the name" part. I'd also be interested to look at the attention patterns for the important heads, on both the gendered and baseline distribution, and at how this changes after key connections are patched in or out. But yeah, overall, solid work, well executed, and interesting findings from a weekend - very much the kind of work that I wanted to come out of this hackathon! I hope you continue investigating this after the weekend :)
See the code and research.
Automated identification of potential feature neurons
By Michelle Lo
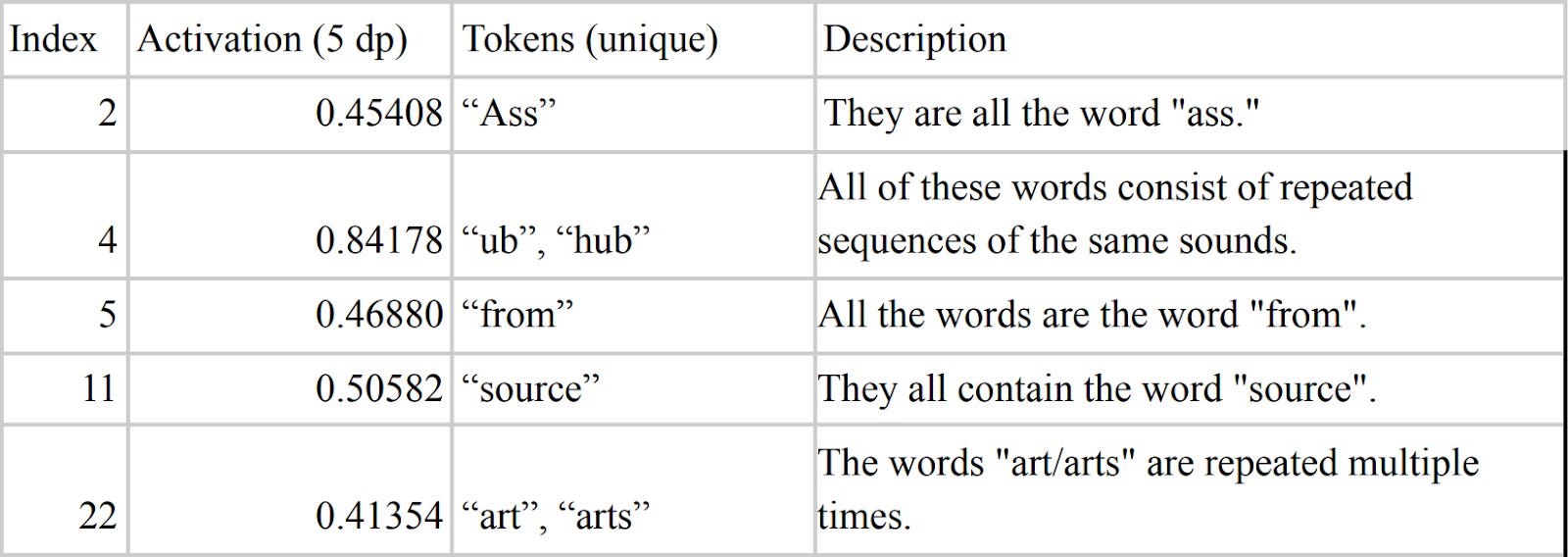
Abstract: This report investigates the automated identification of neurons which potentially correspond to a feature in a language model, using an initial dataset of maximum activation texts and word embeddings. This method could speed up the rate of interpretability research by flagging high potential feature neurons, and building on existing infrastructure such as Neuroscope. We show that this method is feasible for quantifying the level of semantic relatedness between maximum activating tokens on an existing dataset, performing basic interpretability analysis by comparing activations on synonyms, and generating prompt guidance for further avenues of human investigation. We also show that this method is generalisable across multiple language models and suggest areas of further exploration based on results.
The method consists of three steps:
Get top 20 texts from the training set where each neuron activates and use FastText to compare semantic similarity of these top 20 examples. Identify semantically coherent neurons by filtering for internal token similarity.
For each token, take the top 5 similar tokens with FastText and add the token if it presented an increase in the neuron activation, indicating that it responds to a feature and not just to specific words.
With the significantly semantically activating neurons and their top tokens, GPT-3 can then be used to describe the similarity between the tokens for each neuron, leading to a human-understandable and highly-compressed understanding of the semantic encoding of a neuron. Each token has a 7 token symmetrical context window that enables this description.
Neel’s comment: Cool project! I'm excited to see Neuroscope being used like this (and I'm sorry you had to scrape the data - I need to get round to making the dataset available!) I liked the creativity and diversity of your methods, and like the spirit of trying to automate things! Using GPT-3 and FastText are cool ideas. My main criticisms are that I think these descriptions tend to not be specific enough and miss nuance, eg neuron 134 in layer 6 of solu-8l-pile is actually a neuron that activates on the 1 in Page: 1 in a specific document format in the pile, and seems way more specific than the description given! https://neuroscope.io/solu-8l-pile/6/134.html I also think that tokenization is a massive pain, that breaks up the semantic meaning of words into semi-arbitrary tokens, and I don't see how your method engages with that properly - it seems like it mostly doesn't involve the surrounding context of the word? I really liked the idea of substituting in synonym tokens for the current token, I'd love to see that done for the 5 tokens before the current token, and to try to figure out if we can find "similar tokens" in a principled way, when the token is not just a word/clear conceptual unit. But yeah, overall, nice work!
Soft prompts are convex sets
By Amir Sarid, Bary Levy, Dan Barzily, Edo Arad, Gal Hyams, Geva Kipper, Guy Dar, Itay Yona, Yossi Gandelsman
Abstract: We researched prompt tuning on GPT-2 for various tasks, with our main conclusion being that the embedding space for prompt tuning tasks is convex. We tried several iterations of training on the same prompt tuning task, each reaching different results, and then checked different convex combinations and saw that they reached a similar success rate in those same tasks. This implies that the different possible ways to solve this task might all come from a single convex set of valid solutions, and allows us to generate many various solutions that all achieve similar results on the task at hand.
The team attempted several experiments and found that multiple tokens that accomplish the same task (e.g. simple addition) can create combinations of their token vector set that still have good performance on the task.
Neel’s comment: I'm not sure how compelled I am by specific results here, but this was a cool project idea, you tried sensible things, and it's technically hard enough that I'm impressed by the amount you got done!
See the code and research.
Other research
Besides the top four projects, we saw great work from other teams. Here are short descriptions of five more projects and we suggest that you check out the rest if you are interested.
A comparison of the mechanistic circuits of a trained toy model Transformer and a TracR-compiled Transformer on a sentence reversal task (read more).
Introducing a method to embed attention heads into a similarity space (read more).
Extending the CCS approach with a reward internal coherence confidence regularizer (read more).
Creating interactive web apps, one for creating mechanistic interpretability plots on the web (see the app) and another for visualizing whole layers' activations to tokens (see the colab).
The Alignment Jam
This alignment hackathon was held online and in 11 locations at the same time with 15 projects submitted on mechanistic interpretability. $2,200 in prizes were given out for the top projects and the final judging choice was made by the judges (Neel Nanda).
Follow along with upcoming hackathons on the Alignment Jam website and join the interpretability hackathon happening this weekend, again with Neel Nanda.