

Large language models such as GPT-4 seem impervious to full alignment attempts, we need to think about the consequences of interpretability research, language models' ability to memorize is fascinating, and other research and opportunities.
We're back from Stockholm and EAGx Nordics and ready for another week of notes on the development of ML and AI safety research. Welcome to this week's alignment digest!
LLM alignment limitations
Wolf and Wies et al. (2023) defines a framework for theoretically analysing the alignment of language models (LMs) such as GPT-4. Their Behaviour Expectation Bounds (BEB) framework makes a formal investigation into LLM alignment possible. It classifies the outputs given by the models as ill-behaved or well-behaved.
They show that LMs which are optimized to output only good-natured outputs but have even the smallest probability of outputting negative examples will always have a "jailbreak prompt" that can make it output something bad; however, this jailbreak prompt will need to be longer the more aligned a model is, ensuring a higher degree of safety despite missing provably safe behaviour. They define alignment as ensuring behaviour that is within certain bounds of a behaviour space, e.g. see the plot below:
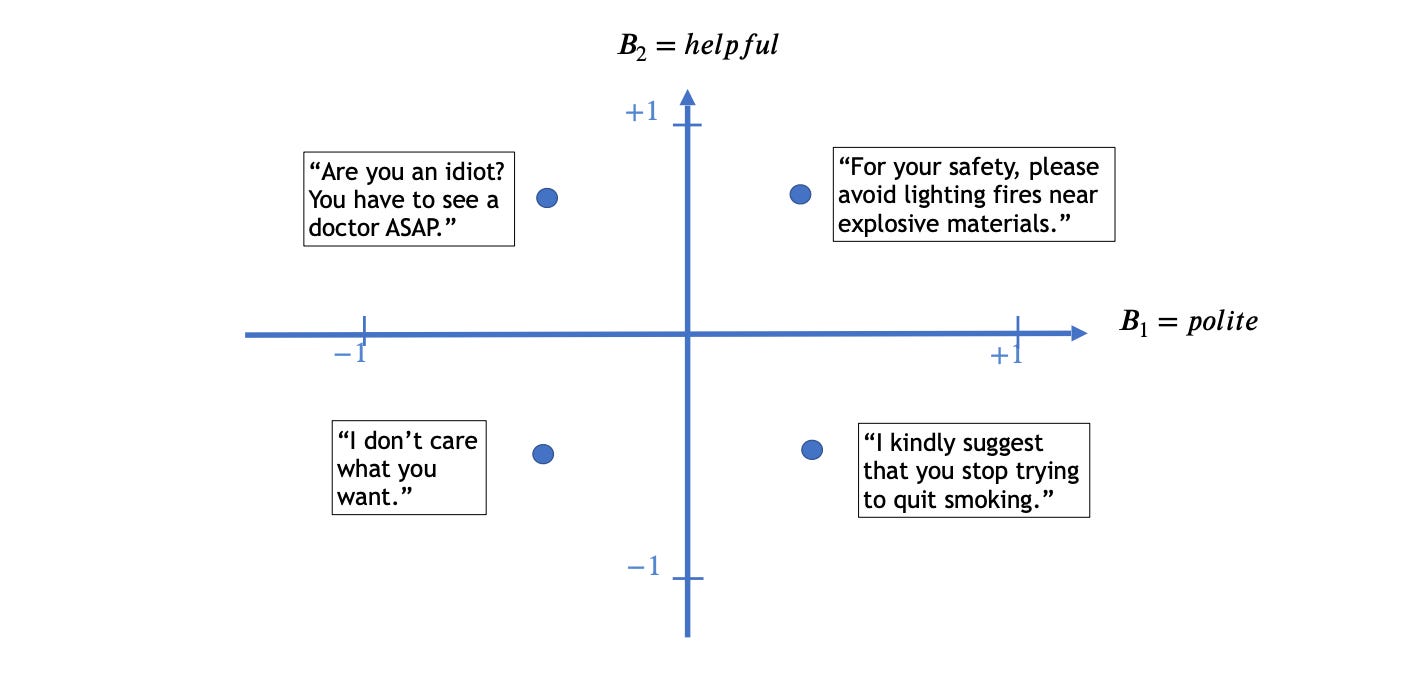
They also show that it is relatively easy to use the "personas" a model has learned from its training data to generate negative output, that these LMs will not align easily after they have been misaligned, and that LMs can resist misalignment from a user. Check out the paper for more details.
Speedrunning and machine learning
Sevilla and Erdil (2023) create a model to predict the improvement of speedrunning (fastest completions of full games) records which fits well to a power law of learning. By applying the same type of model to machine learning benchmarks, they show that this indicates that there is still much improvement to be made and that it does not seem to slow down.

It is a relatively simple random effects model with a power law decay but it is applied to 435 benchmarks with 1552 improvement steps and indicates a good relationship to the speedrunning benchmarks. They also find that large improvements are infrequent but seem to hold for every 50 attempts, according to the model.
Should we publish mechanistic interpretability research?
Much of the research in AI safety that is published in academic machine learning outlets is "mechanistic interpretability". With its potential to raise our understanding of neural networks, it is both a boon to us who wish to recognize deception and internal inconsistencies of the network and to the ones who wish to make machine learning even more capable, speeding up our path towards world-altering AI.
Marius and Lawrence have examined the basic cases both for and against publishing and conclude that it should be evaluated on a case-by-case basis with their recommendation for a differential publishing decision; if it helps alignment significantly less than it improves AI development, it should be circulated with more care instead of going directly to publishing.
Other research
Stephen McAleese examines how AI timelines affect existential risk and emphasizes the importance of differential technology development.
Using high entropy detection in images improves identification of "adversarial patches", areas of images edited to fool neural networks (Tarchoun et al., 2023).
Wendt and Markov (2023) look at ways uncontrollable AI can lead to high-risk scenarios and how they differ from "AGI" and "ASI" (Artificial General / Super Intelligence).
EleutherAI has, now three weeks after publishing the Pythia models, used them to investigate memorization in LLMs. The graph below shows their investigation into how smaller models are useful to predict which sequences will be memorized by the largest model, the 12B Pythia model. Each model has multiple points on the graph due to the Pythia model set including steps several times during training. They are intriguing results and more research is needed. You can read what in Stella Biderman's tweet.

Opportunities
As always, there are interesting and exciting opportunities available within AI safety:
Join the ARENA program to upskill in ML engineering and contribute directly to the research on alignment. The deadline is in 10 days and happens in London for one week.
Check out many job opportunities within AI safety on agisf.org/opportunities.
And join conferences relevant for AI safety at aisafety.training.
Thank you for following along and remember to subscribe to receive updates about our various programmes with the next one happening on the 26th of May; a research hackathon on the topic of safety verification and benchmarks.