
Scroll to the bottom for an update on your subscription to this mailing list.
Project updates
Our projects have progressed quite a bit since the last update we shared with you all. We have become more focused on AI safety research facilitation and growth than direct research.
We do this by creating scalable and accessible research access and opportunities in three integrated projects: 1) The alignment research update series, 2) alignment hackathons, and 3) the AI Safety Ideas collaborative research platform. These projects work together to create opportunities for continued engagement and practical research experience in one funnel.
AI Safety Ideas
We have published the AI Safety Ideas platform again after a hiatus that came about because of our shift towards direct research. You can read the release post here.
Now, it is again a core part of our strategy to support and facilitate research in AI safety and there's a roadmap for the development that enables hypothesis testing, bounties for solving hypotheses, decentralized project collaboration, custom lists, event integrations, DOIs, and peer review.
We have heard a lot of positive feedback on this and several local AI safety organizers, AI safety researchers, and the AGISF team have mentioned that they see opportunity in this sort of platform getting a lot of traction.
Some of the largest development challenges we see is ensuring it does not become too crowded informationally, that you can still navigate the ideas, and the specific design of the knowledge graph between ideas.
The risks from a research perspective are mostly covered in the post but TLDR; we will try to ensure a diversity of perspectives on the platform, that projects are not capabilities, and interview users to ensure they draw value from the platform.
Alignment Jam hackathons
One of the events that we will integrate with the platform is the Alignment Jam hackathons. Visit our website for the hackathons here.
The alignment jams are a new type of hackathon event where we take care of the hard parts of a topic, agenda, prizes, merch, starter templates and code, and expenses and local organizers create in-person "jam sites" and take care of marketing to local mid-career researchers and engineers, have at least one volunteer on site for the whole weekend, and take care of venues.
We have already organized one hackathon with one in-person location and a virtual hackathon space (see the results, the follow-up survey data, and more). Ian McKenzie was the intro speaker and the participants worked on projects around the theme "Cognitive Science on Language Models".
The next hackathon will be about interpretability research and will be held in 3 physical locations (UCL / Imperial / King's / LSE, Aarhus University, and Tallinn) along with the virtual space.
Respond to this email if you have ideas for hackathon topics, want to be a speaker, or have other comments.
Weekly alignment update series
We have started our alignment update series currently named "ML Safety Updates" for 7 weeks. They are available in podcast, YouTube, newsletter, and LessWrong formats.
We have had a lot of traction and several commenters have mentioned that they love the series. We just started putting them in other formats than YouTube and look forward to the response we'll get from the research community!
Check out the latest video below:
In-house research
The last time we wrote, our in-house research was focused on the Scaling Laws research submissions along with investigations into implementations of AI with empathy.
We have since then discontinued our AI with empathy project but will release the dataset and graphs from the project as either a blog post or an ArXiv systematic review. The 2nd round of the Scaling Laws prize ends in a few days and we have one submission for this round as well.
Now, we also have a research paper accepted for NeurIPS from Fazl Barez on integrating environmental constraints in exploration during training to avoid catastrophic search scenarios.
Another project focuses on symbolically interpretable features extracted from a language model. This work continues some of the work that happened at Amazon for their ML hiring optimization that Fazl was also a part of.
Another interesting project is the Safety Timelines research that we published to the Forum that tries to quantify how we should update our Doom estimates based on the timelines for when alignment might be solved.
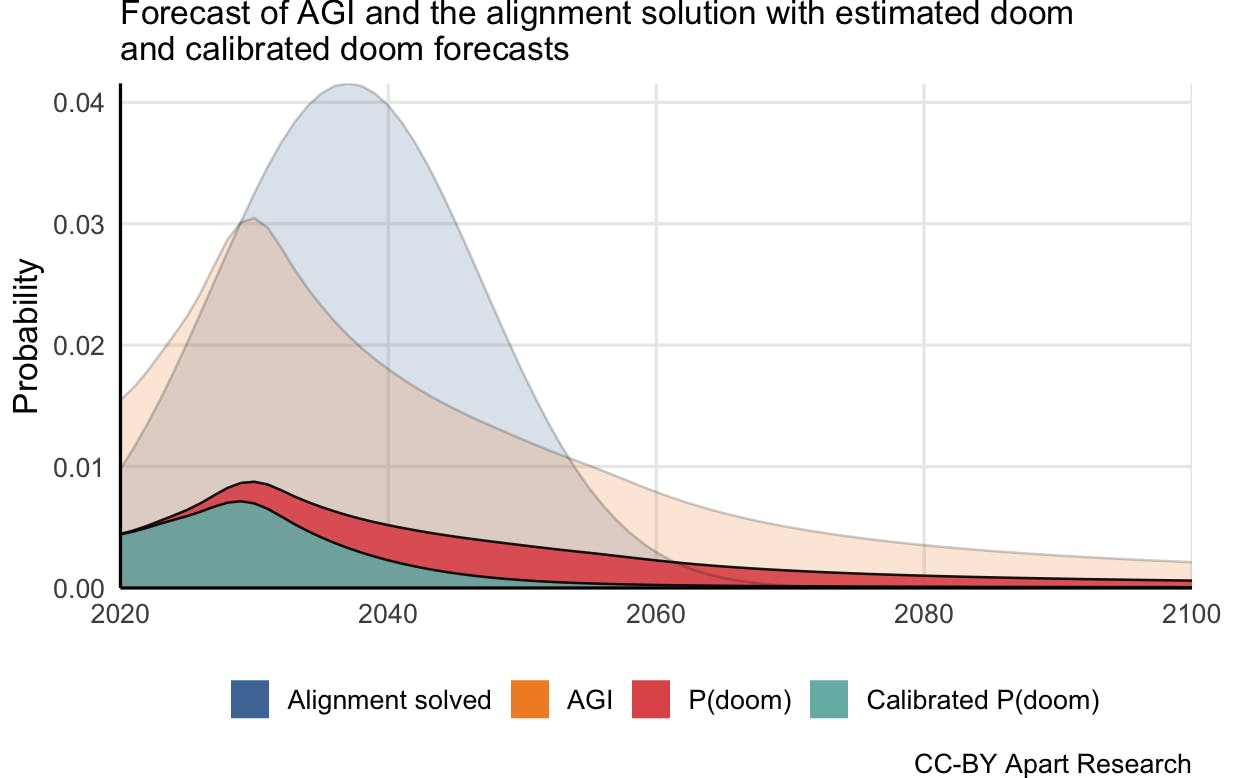
We have a follow-up post in the works analyzing how long it has taken for mathematics conjectures to get proofs and relates AI safety research development to energy technology development
Following our projects
Since this mailing list was created, we have initiated three new mailing lists so you can decide which parts of our projects to follow.
You are already on the mailing list for Apart Research updates but you can subscribe to the Alignment update series, updates about the hackathons, and updates about the development on AI Safety Ideas.