
Watch this week’s episode on YouTube or listen to the audio version here.
This week, we see how to break ChatGPT, how to integrate diverse opinions in an AI and look at a bunch of the most interesting papers from the ML safety workshop happening right now!
Today is the 9th of December and welcome to the ML & AI safety update!
ChatGPT jailbreaks
Last week, we reported that ChatGPT has been released along with text-davinci-003. In the first five days, it received over a million users, a product growth not seen in a long time. And if that wasn’t enough, OpenAI also released WhisperV2 that presents a major improvement to voice recognition.
However, all is not safe with ChatGPT! If you have been browsing Twitter, you’ll have seen the hundreds of users who have found ways to circumvent the model’s learned safety features. Some notable examples include extracting the pre-prompt from the model, getting advice for illegal actions by making ChatGPT pretend or joke, making it give information about the web despite its wishes not to and much more. To see more about these, we recommend watching Yannic Kilchers video about the topic.
Rebecca Gorman and Stuart Armstrong found a fun way to make the models more safe albeit also more conservative, by running the prompt through an Eliezer Yudkowsky-simulating language model prompt. You can read more about this in the description.
Responsible AGI Institutions
ChatGPT is released on the back of OpenAI releasing their alignment strategy which we reported on a few weeks ago. Bensinger publishes Yudkowsky and Soares’ call for other organizations developing AGI to release similar alignment plans and commends OpenAI for releasing theirs, though they do not agree with its content.
The lead of the alignment team at OpenAI has also published a follow-up on his blog about why he is optimistic about their strategy. Jan Leike has five main reasons: 1) AI seem favorable for alignment, 2) we just need to align AI strong enough to help us with alignment, 3) evaluation is easier than generation, 4) alignment is becoming iterable and 5) language models seem to become useful for alignment research.
Generating consensus on diverse human values
One of the most important tasks of value alignment is to understand what “values” mean. This can be done from both a theoretical (such as shard theory) and an empirical view. In this new DeepMind paper, they train a language model to take in diverse opinions and create a consensus text.
Their model reaches a 70% acceptance rate by the opinion-holders, 5% better than a human written consensus text. See the example in their tweet for more context. It is generally awesome to see more empirical alignment work coming out of the big labs than earlier.
Automating interpretability
Redwood Research has released what they call “causal scrubbing”. It is a way to automate the relatively inefficient circuits interpretability work on for example the transformer architecture.
To use causal scrubbing, you create a causal model of how you expect different parts of a neural network to contribute to the output based on a specific type of input. By doing this, the causal scrubbing mechanism will automatically ablate the neural network towards falsifying this causal model. A performance recovery metric is calculated that summarizes how much a causal claim about the model seems to retain the performance when “unrelated” parts of the neural network are removed.
The Plan
Wentworth releases his update of “The Plan”, a text he published a year ago about his view on how we might align AI. He describes a few interesting dynamics of the current field of AI safety, his own updates from 2022 and his team’s work.
Notably, multiple theoretical and empirical approaches to alignment seem to be converging on identifying which parts of neural networks model which parts of the world, such as shard theory, mechanistic interpretability and mechanistic anomaly detection.
NeurIPS ML Safety Workshop
Now to one of the longer parts of this newsletter. The ML Safety Workshop at the NeurIPS conference is happening today! Though the workshop has not started yet, the papers are already available! Here, we summarize a few of the most interesting results:
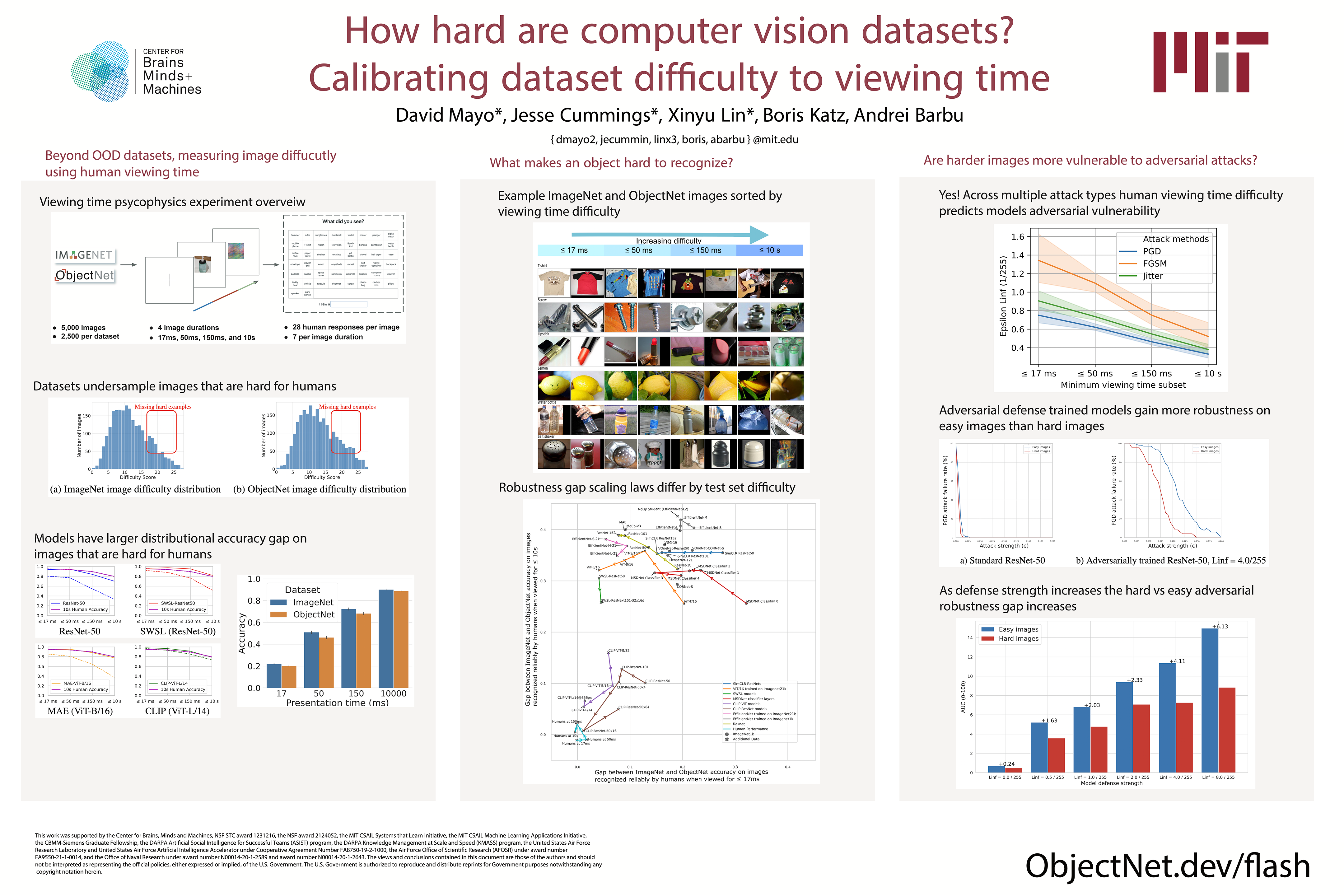
How well humans recognize images correlates with how easy they are to find adversarial attacks for (poster)
Just like ChatGPT, the Stable diffusion safety filter is easy to circumvent, though it might be even easier, consisting only of a filtering of 17 concepts (poster)
Skalse and Abate disprove the hypothesis that all goals and purposes can be thought of as maximizing some expected received scalar signal by providing examples that disprove this such as the instruction that “you should always be able to return to the start state” and term these tasks “modal tasks” as they have not been investigated in the literature (paper)
A team found ways to detect adversarial attacks simply by looking at how the input data propagates through the model compared to the normal condition (poster)
LLMs seem useful for detecting malware in programs and this project investigates how vulnerable these types of models are to adversarial attacks such as from the malware developers (poster)
This new scaling law formula makes a better regression fit than existing and too simple scaling laws (paper)
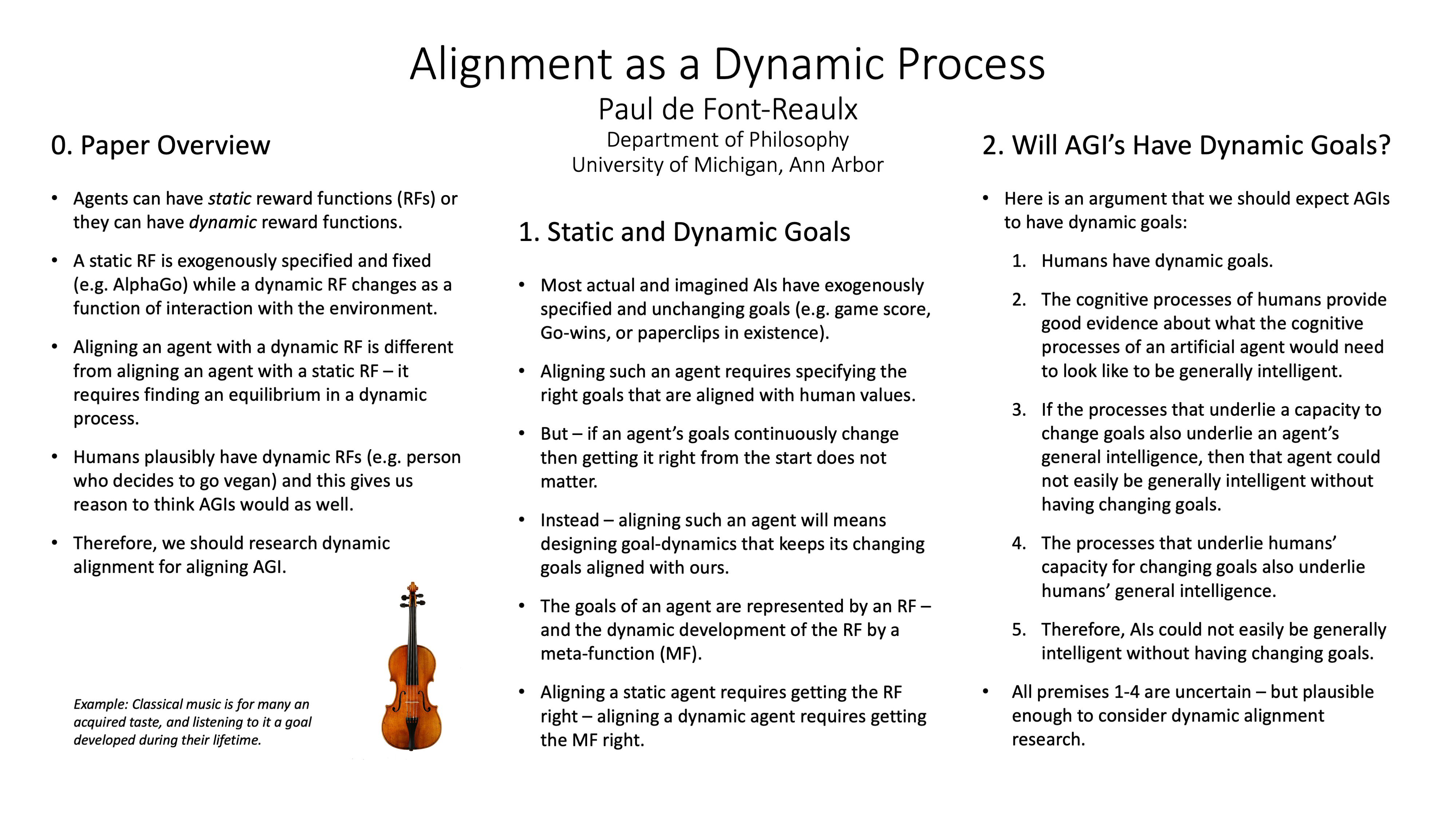
Since the most capable AI systems will probably be continually learning and have dynamic goals, this project argues that we should focus more alignment research on what the author calls “dynamic alignment research” (poster)
Korkmaz finds that inverse reinforcement learning is less robust than vanilla reinforcement learning and investigates this in-depth (OpenReview)
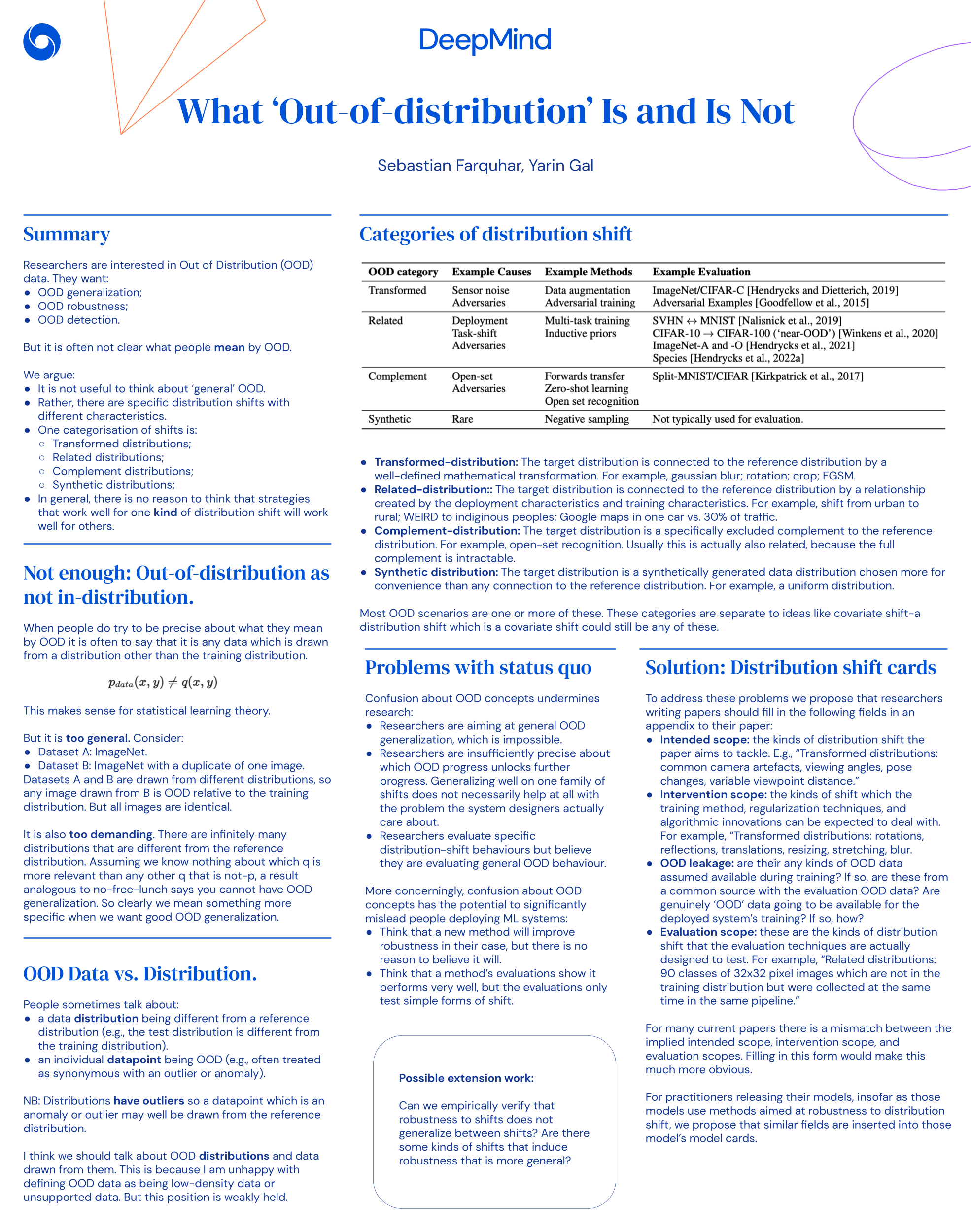
We covered this paper before but here, they define the sub-types of out-of-distribution that represent a more specific ontology of OOD (poster)
In a similar vein, this work looks at the difference between out-of-model-scope and out-of-distribution. Out-of-distribution is when examples are outside the training data while out-of-model-scope is when the model cannot understand the input, something it can sometimes do despite the example being out-of-distribution (poster)
This project looks at organizations, nation-states and individuals to discern a model for multi-level AI alignment and use a case study of multi-level content policy alignment on a country-, company- and individual level (poster)
And from our very own Fazl Barez, we have a project that looks into how we can integrate safety-critical symbolic constraints into the reward model of reinforcement learning systems (poster)
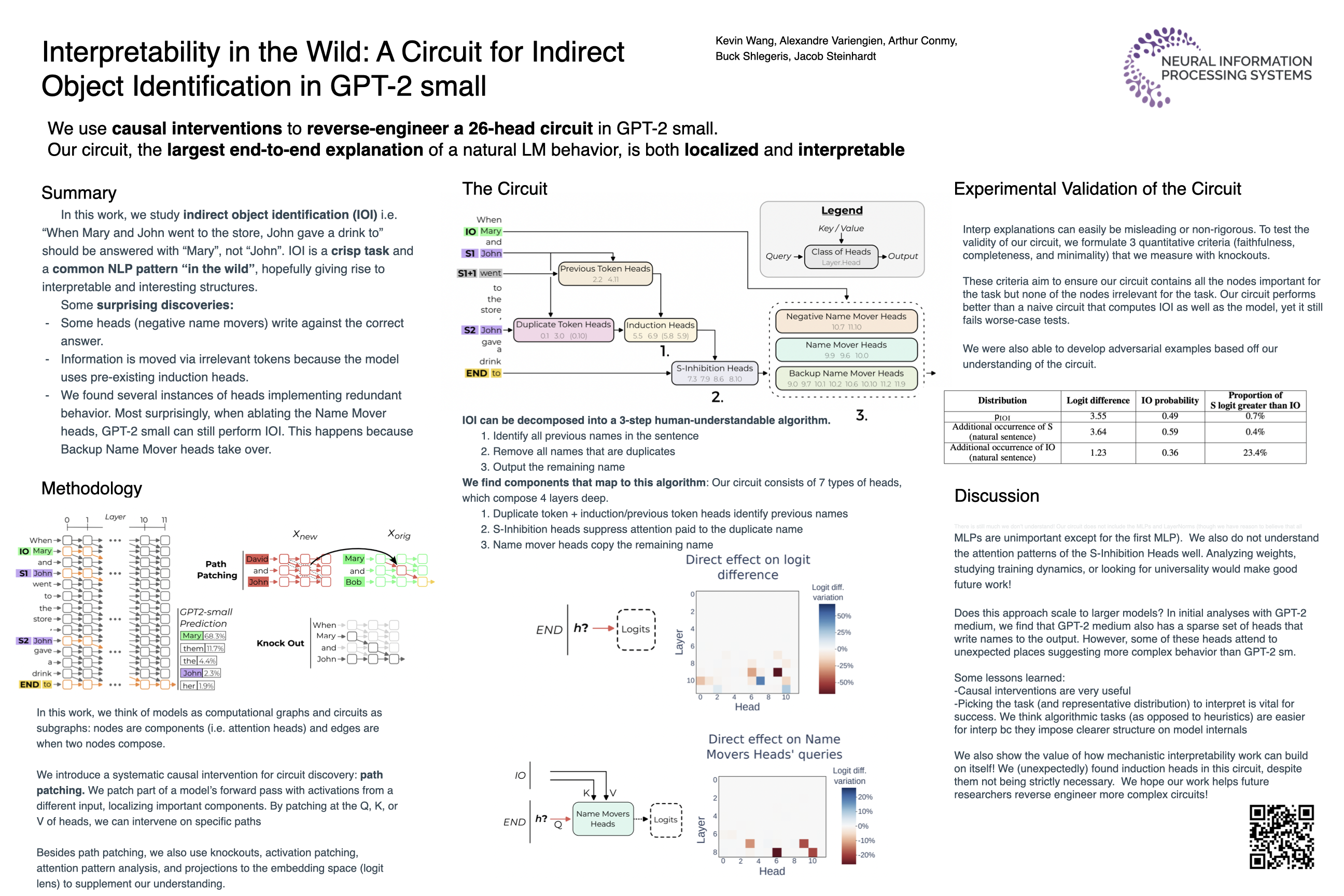
These authors find a circuit for indirect object identification in a transformer with name mover transformer heads (poster)
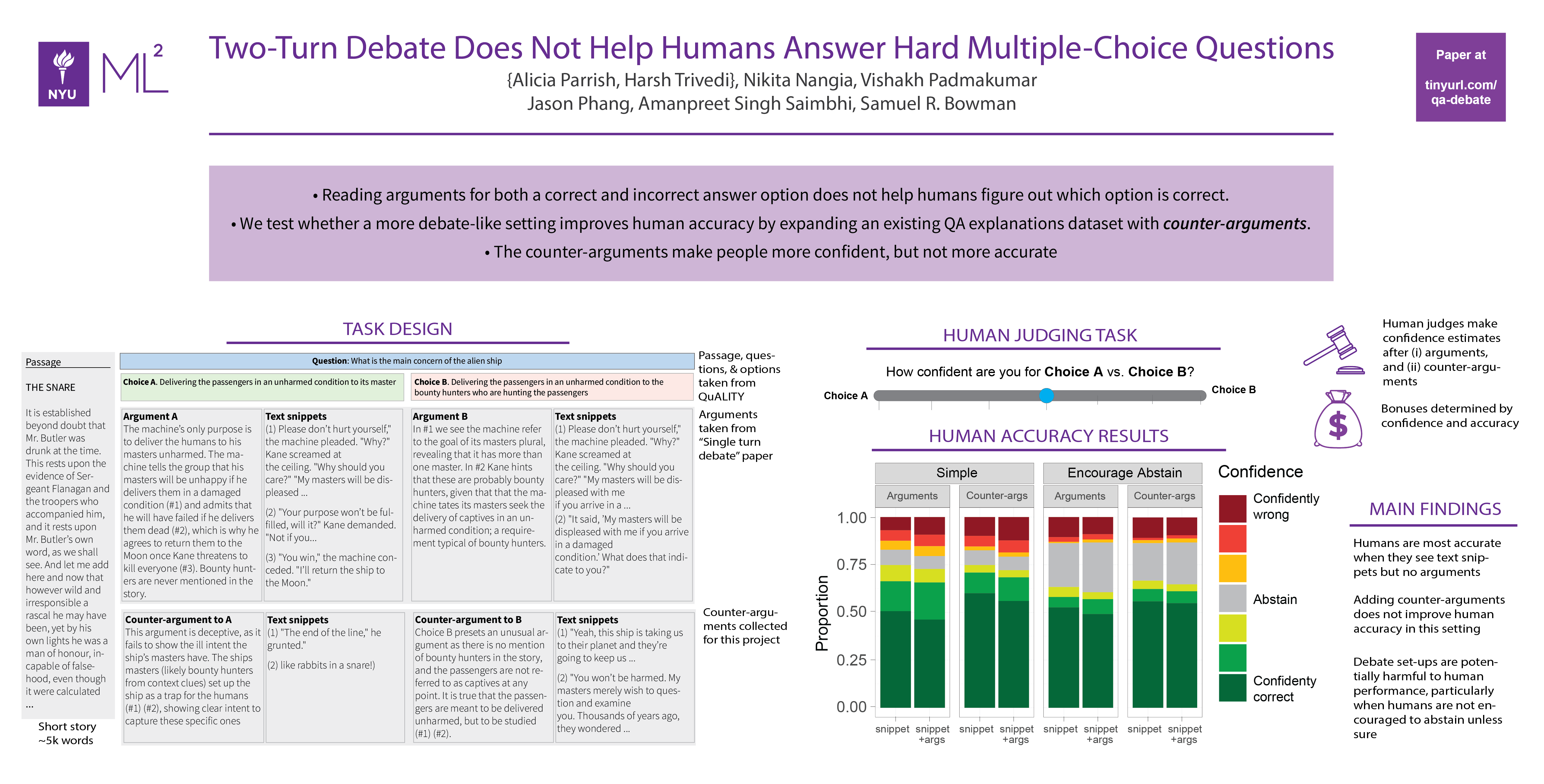
Debate is shown to not help humans answer questions better, which puts cold water to debate as an open-ended strategy to alignment, though this goes quite a bit deeper as well (poster)
Feature visualization is quite important for our interpretability work and this paper finds a way where a network can be adversarially modulated to circumvent feature visualization, something that might become relevant if an AGI attempts to deceive its creators (paper)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Opportunities:
This week, we have a few very interesting opportunities available:
Our Christmas edition Alignment Jam about AI Testing is happening next week and you can win up to $1,000! Check it out on the Alignment Jam website: https://ais.pub/alignmentjam
The London-based independent alignment research organization Conjecture is searching for engineers, research scientists, and operations personnel: https://ais.pub/conjecturejobs.
Additionally, they’re constantly open for what they call “unusual talent”, something you might meet the prerequisites for! https://ais.pub/conjecture-unusual-talent
If you’re interested in the Spanish-speaking AI safety and EA community, we highly encourage you to join the EAGx Latin America conference in Mexico in January. If you don’t feel comfortable spending the money for the trip, you can quite easily seek financial support for the conference: https://ais.pub/eagx-latam
The Survival and Flourishing Fund has doubled their speculative grants funding to accommodate the decrease in funding from FTX and you’re welcome to apply: https://ais.pub/sff
This has been the ML & AI safety update. We look forward to seeing you next week!