
What a week.
There was already a lot to cover Monday when I came in for work and I was going to do a special feature on the Japan Alignment Conference 2023 and watched all their recordings. Then GPT-4 came out yesterday and all my group chats began buzzing.
So in this week's MLAISU, we're covering the latest technical safety developments with GPT-4, looking at Anthropic's safety strategy, and covering the fascinating Japanese alignment conference.
Watch this week's MLAISU on YouTube or listen to it on Podcast.
GPT-4: Capability & Safety
GPt-4 was just released yesterday and it is just as mind-blowing as GPT-3 was when it was released. To get a few technical details (from the report) off the ground:
GPT-4 is multimodal which means it can interact both with images and text
Bing has been using GPT-4 for its functionality
It can take in about 50 pages of text now compared to 7 before
Some inverse scaling tasks do not scale inversely on GPT-4
It scores an IQ of 96 compared to 83 for GPT-3
They also write (in 2.9) that the model shows more and more independent behavior, seemingly mimicking some of the risks we associate with uncontrollable AI, such as power-seeking and agenticness (the ability to have an identity, possibly leading to goal-directed behavior independent of us users' preferences).
The Alignment Research Center also describes an experiment in the report where they upload GPT-4 to its own computer and give it some money and abilities such as delegating tasks to versions of itself and running code. This is done to test for the ability to self replicate, a big fear for many machine learning practitioners.
They also collaborated with many other safety researchers to "red team" the model, i.e. find safety faults with GPT-4. In the report, it is explicitly stated that participation in this does not mean endorsement of OpenAI's strategy, but the gesture towards safety is very positive.
Additionally, they do not share their training methods due to safety concerns, though it seems just as likely that this is because of the competitive pressure of other AI development companies (read more on race dynamics).
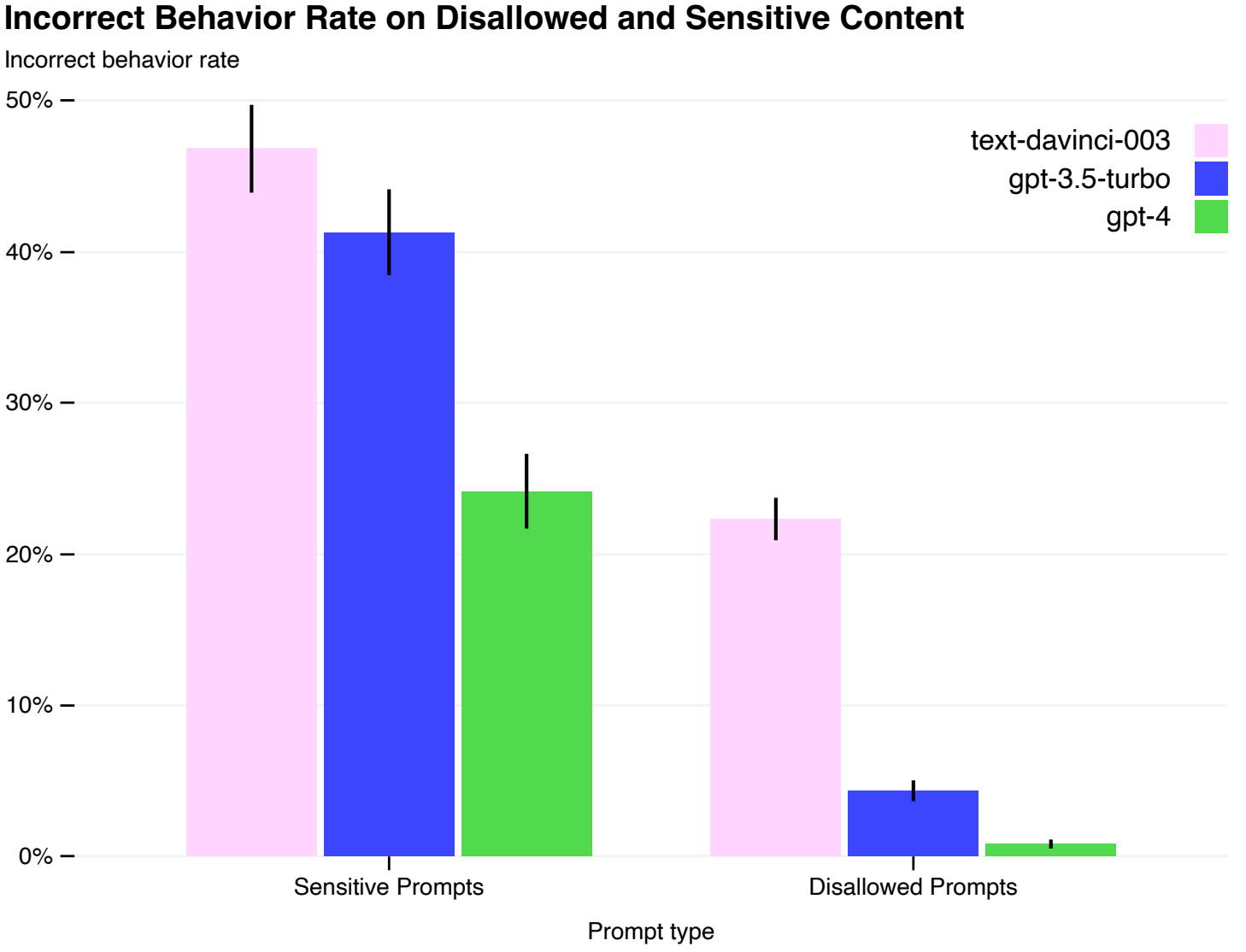
GPT-4 is seemingly safer while being significantly more capable
Anthropic & Google's response
On the same day, Anthropic released a post on their updated availability for Claude, their ChatGPT-like competitor. It uses the "constitutional AI" approach which essentially means that the AI evaluates its outputs using a ruleset (constitution) on top of learning from human preferences.
They also published their approach to AI safety. Anthropic writes that AI will probably transform society and we don't know how to consistently make them behave well. They take a multi-faceted and empirical approach to the problem.
This is based on their goal of developing (I) better safety techniques for AI systems and (II) better ways of identifying how safe or unsafe a system is. They classify three possible AI safety scenarios: (I) That it is easy to solve or not a problem, (II) that it might lead to catastrophic risks and it is very hard to solve and (III) that it is near-impossible to solve. They hope and work mostly for scenarios (I) and (II).
Additionally, Google joins the chatbot API competition by releasing their PaLM language model as an API. Generally, Google seems to be lagging behind despite their research team kickstarting the large language models research, which seems like a large business failure but might be good for AI safety. However, the AGI company adept.ai also recently raised $350 million to build AI that can interact with anything on your computer.
Japanese Alignment Research
I watched all six hours of talks and discussions so you don't have to! The Japan Alignment Conference 2023 was a two-day conference in Tokyo that Conjecture held in collaboration with Araya, inviting researchers to think about alignment.
It started with a chat with Jaan Tallinn, who wants the Japanese researchers to join in the online discussions of alignment, and an introduction to the alignment problem. Connor Leahy and Eliezer Yudkowsky had a Q&A discussion and Siméon Campos presented a great introduction to how AGI governance might go about slowing down AGI development. Jan Kulveit also gave great presentations on active inference and AI alignment along with his expectation of "cyborg periods" between now and superintelligence.
But focusing on the talks from the Japanese side, we see some quite interesting perspectives on alignment:
Researchers from the Whole Brain Architecture Initiative presented their path from neuroscience research in 2007-2011 into artificial general intelligence development until now where they are reframing their approach to fit with the radical intelligence increase. Their tentative next mission is to provide technology to make AI more human, hopefully increasing understanding and safety.
A reinforcement learning team from Araya wants to replicate biological systems interacting in real life to create aligned AI.
Tadahiro Taniguchi from Ritsumeikan University presented on "symbol emergence" in robotics, how we can train AI to understand segmentations of the world (e.g. a table vs. a piece of wood in the table) and assign categories (symbols) to them.
Shiro Takagi is an independent researcher focusing on process supervision on large language models. This is similar to Ought's factored cognition.
Ryota Kanai from Araya spoke about the global workspace theory as a good representation of brain and AI functions. They have experimented with connecting two monkeys' brains to coordinate their disparate latent spaces, which basically just means to synchronize the type of understanding the two brains do. He also spoke briefly about consciousness and didn't expand on the alignment implications of such work.
Hiroshi Yamakawa and Yutaka Matsuo of WBAI have worked on what the future we want looks like. They define our ultimate goal as having "surviving information" and indicate that we need life to be reproducible autonomous decentralized systems to be robust against extinction. They create a timeline of the digital life revolution with take-off, genesis, coexistence, transformation and stability. They expect "human patterns" of life to disappear and our relationship to superintelligence to develop from an "enslaved God" to a "protector God", if all goes well. Despite the terminology, it is quite a sober and interesting talk and they expect we will have to integrate deeply with technology.
Tadahiro Tamaguchi speaks of the importance of combining multiple ways of interacting with the world to have safer cognitive development of robots.
Manuel Balteri from Araya tried to engage alignment from first principles as a category theorist and dynamical systems theorist. He described how he found surprisingly little material in alignment literature of the basic assumptions: How is an agent, agency and alignment defined? In the talk, he looks at how to define these and does quite a good job of it.
Hopefully, the Japan Alignment Conference will represent some first steps towards collaborating with the great robotics and neuroscience talent in Japan!
Opportunities
There are many job opportunities available right now, with some great ones at top university AI alignment labs: At University of Chicago as an alignment postdoctoral researcher, as an NYU alignment postdoc, as a University of Cambridge policy research assistant and a collaborator with CHAI at UC Berkeley.
And come join our online writing hackathon on AI governance happening virtually and in-person across the world next weekend from March 24th to 26th. Emma Bluemke and Michael Aird will be keynote speakers and we have judges and cases from OpenAI, the Existential Risk Observatory and others.
You can participate for the whole weekend or just a few hours and get the chance to engage with exciting AI governance thinking, both technical and political; get reviews from top researchers and active organizations; and win large prizes.
Join our Discord server to receive updates and click "Join jam" on the hackathon page to register your participation!
And before then, we'll see you next week for the ML & AI Safety Update!